AI is not coming for analyst jobs anytime soon
That is, if you can rise above SQL jockey


This title has the potential to offend two very different groups. Before you take out the pitchfork, let me clarify two things:
For SQL enthusiasts: Our collective SQL skills are still going to be very valuable for at least the next decade.
For AI enthusiasts: Advances in deep learning and in particular the recent larger transformer models (e.g. GPT-3, T5 ) will have a dramatic impact on the industry, just not in the ways most people think.
At ThoughtSpot, we have spent the last decade building an AI-powered analytics engine that sits on top of SQL systems. We have also built one of the fastest SQL processing engines (we built a distributed in-memory database for our customers that are not in the cloud yet) so I am both a huge AI enthusiast and a SQL enthusiast. I have also spent a lot of time figuring out what today’s AI can and cannot do in the data space. This blog is a distillation of learnings from that decade-long quest that should be helpful for the analyst community in understanding what may be coming in the near future and picking what you could prioritize in skill-building.
The summary is that today AI only works in very narrow and well-defined problem spaces. Also, it is very hard to use AI in domains where tolerance for failure is relatively low. As a result, in the data space, AI is primarily useful in either micro-decisions with low stakes (e.g. ranking search results, ranking ads, product recommendations) or with human-in-the-loop products1.

Where AI struggles
Here are some things that are going to be hard for AI to do in the near future:
Adding missing context to data
Data in itself is quite useless until you put it in the real-world context. For example, what do different tables and columns mean, how to interpret data, how different tables are supposed to join is mostly locked inside people’s brain. A column could be named stripe_revenue, but the fact that it represents monthly recurring revenue (MRR) may be missing. There can be 3 different columns called customer in different tables and they may represent a customer in different contexts, but which one to use again requires a lot of contexts. If you try and use AI to extract this kind of knowledge, your best bet would be to use NLP on documents, code comments, or conversations like in Slack channels. But the technology is no way mature enough to come even close to automating this kind of task, and any attempt to do so will produce unreliable information. In the foreseeable future, someone needs to own building usable, well-documented data models for analytics to happen.
Inferring underlying causal structure and processing behind the data
To do a good job of analyzing data, you have to understand the process that generates the data and how it relates. In the absence of knowledge of causal structures in the data we may see:
The algorithms miss an important relationship that may be somewhat obvious to a human mind because they understand the causality.
The algorithms may pick up on correlations that have no causal link or significance to the end-user, causing noise that drowns other significant insights.
The algorithms may not know the significance of a pattern in the data because the relationship between the observable variables in the pattern and the variables that the end user really cares about may not be known. So it becomes hard to rank different insights based on their significance to the end-user and surface the important ones.
For example, ad impressions and Google searches may cause people to visit your website. Visitors on the website navigate from page to page and may transact. These transactions are dependent on users liking what they see and inventory being present. Without understanding all these underlying processes, an AI algorithm won’t understand that you are losing potential revenue and wasting marketing dollars by advertising for a product that is out of stock.

Breaking complex problems into smaller problems
As human beings, one of our most powerful problem-solving tools is our ability to break a complex problem into multiple simpler problems. Take software engineering for example. In some ways, all they are doing is dividing and conquering until they get to primitives that the underlying library or hardware can solve for. There is some evidence that AI can do this in controlled settings. The most famous example in a widely-used product is perhaps the Excel Flash-fill feature, but it is limited to fairly simple functions. Recently DeepMind caught many people by surprise with AlphaCode which performed better than roughly 45% of human participants in a coding competition. While this is impressive, it still works in a very narrow domain of problems with lots of training data on those problems.
In the context of analytics, breaking a problem into pieces may mean breaking cohort analysis into sub-queries, required sub-queries, or first transforming data into an easy-to-analyze data model and then doing the analysis. Even if we look at the most state-of-the-art AI, we won’t be able to automate such things for several years.
Adding context to data questions
This is an area where I have spent a lot of time exploring. I’ll give a few motivating examples first:
We were talking to an airline and they have two important metrics: A0 = “Average arrival delay for a flight segment” and D0 = “Average departure delay for a flight segment.” When someone asks what A0 for DFW means, it means A0 where Arrival_Airport = DFW. Alternately when someone asks What is D0 for DFW, it means D0 where Departure_airport = DFW. This context is very specific to that customer and you cannot learn this from data available in the public domain.
One customer that represents a large fraction of global corporate travel asked, How many customers are in New York today? This means that their departure date was before today, arrival date was after today, and New York was the destination of their travel. Their data model contains “New York” in close to 20 different columns.
In a database of movies, someone asks what is the longest movie ever? To answer the question, you need to understand that longest in this question means duration. This is something that a model that has a general understanding of the world should be able to figure out. Below is a pretty reasonable answer from GPT-3. GPT-3 is acting more like a search engine here and extracting the right phrases from its training but with some effort, it can be inferred that “longest” means duration.

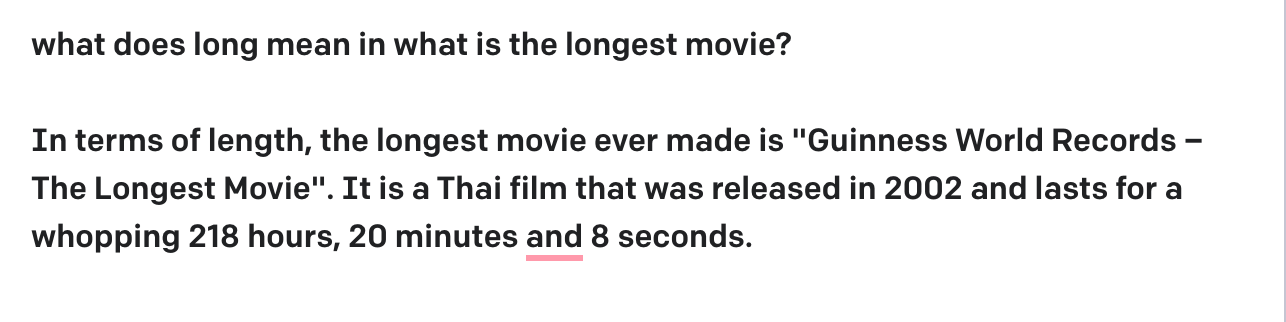
Our experience with this class of problems is that most can be solved with >90% accuracy using ML. But if you try to go from arbitrary natural language to SQL directly, it often requires getting multiple disambiguation problems right, and it is hard to do it today with greater than 80% accuracy. In an analytics product, this kind of accuracy is not acceptable. This is why at ThoughtSpot our search engine avoids any probabilistic inference when interpreting a query.
Where AI succeeds
Now that we have talked about all the difficulties, let’s cover how AI, when used with the right combination of systems and UX, is a really powerful tool in the data space. It is already having a transformative impact on many data teams.
Making low stakes repeated decisions

If each individual decision does not have a large impact and needs to be done millions of times, it is a perfect candidate for AI. This is where most of the enterprise ML sits today whether it's deciding what ads to show, what products to recommend, or which transactions to flag as potential fraud.
At large enterprises, this work cannot be done with a human in the loop. Instead, it was traditionally done with heuristics, and machine learning models can definitely improve upon these decisions. With enough scale, this can have a tremendous impact. During my five years at Google, my small team of ML engineers contributed close to a billion dollars in incremental revenue through feature engineering and ML improvements. While a lot of this work was generating hypotheses and improving algorithms, a big part of the work was analyzing. Every hypothesis about how the predictions could be improved could be quickly validated or invalidated by running analytics on the prediction errors. In that sense, I feel it is great for analysts to expand their understanding to at least the basics of ML. Because a good analyst can be an extremely valuable part of an ML team.
Democratizing the wisdom of the crowd
Have you ever wondered what makes Google so smart that when you search for pain in the bottom of my foot it gives you results about plantar fasciitis? There are many things at play here, but the primary source of this intelligence is us, the users. Some users somewhere queried “pain in the bottom of my foot” and followed it up in the session by a query on “plantar fasciitis” and then clicked on the result. This allows Google to learn the association and help the rest of the billions of users when they need the right answer.
The same idea works for analytics as well. When you learn from users and use that to give personalized recommendations to each user, it dramatically improves their experience and reduces the level of difficulty for them to get the right answer. There may be three different definitions of revenue in your data model, but usually, there is one that gets the most use by people in similar roles as you. When you ask for “Closed bookings this quarter” Usually This quarter maps to the “close date” column, while when you ask for the “pipeline created this quarter”, quarter maps to the “creation date” column. These kinds of recommendations in an auto-completion setting become fairly easy to make if you have a Machine Learned model helping users.
Exploring a large space looking for patterns and anomalies
Suppose, at the end of the month your leadership team is doing a business review and someone says that compared to last year we made 10% less from electronics sales this year. Why would that be? All of a sudden a lot of eyebrows are raised, hypothesis after hypothesis flying in the room. Maybe it's the pandemic and people facing hardships are not buying as much as before. If that is the case, we should see some zipcodes drop a lot more than others. Maybe it is that people are not buying more high-end gear as much as they used to. If that is the case, some price buckets should have much lower revenue than others. After a lot of stress, and a lot of calls to the analytics team, you figure out that it was a lack of inventory for specific products supplied by a specific supplier. This doesn’t need to be a manual process. After the right data model has been built by an analyst and the ML algorithms have learned enough from the history of users asking questions, AI algorithms can do a much better job of searching through hundreds of auto-generated hypotheses looking for a root cause.
This kind of automation works not just for monitoring and root cause analysis, but for all kinds of interesting insights. I have seen manufacturing companies save millions of dollars by finding price discrepancies between suppliers, banks save millions of dollars by letting automated algorithms search for lost claims guided by machine-learned systems. One of the most amusing examples of this was that one of our customers was able to spot that sales for fidget spinners were growing fast way before most people realized that it was a trend using automated insights back in 2017.
Language modeling over domains with a large amount of data
Large-scale language models are a really powerful tool. The most well-known model in this class is GPT-3, but every few weeks we do significant research advancing the state of the art in this space. Building analytics products out of these models is still too early. Some obvious uses are 1. Auto-completion for a SQL/code editor, 2. natural language to code translation, 3. natural language generation to describe insights in the data 4. Conversational data apps to reduce UX complexity. The biggest barrier I see in this space is that if there is any missing context in the input, then it is hard for language models to fill it. Also, if you are trying to model a language with little training data, you can try transfer learning and it can do non-trivial things but building a usable product here will still require either a lot of hand-crafted systems or a little more maturity in language modeling.
Progressive disclosure of complexity
Even though AI today is imperfect, one of the best ways to deploy it in products is to support it with UX. One of the key design principles for us here at ThoughtSpot has been less input more output or LIMO. This means we want the user to do as little work as possible while getting the most value.
Analyzing data, creating visualizations and building data models is all input-intensive work. We try to eliminate as much input (and intellectual burden) as possible by predicting at least part of the input and making an explicit choice for the user. If we get it right, the user can simply move on. If we don’t get it right, the user can edit those decisions. This is one of the big reasons why ThoughtSpot allows thousands of non-technical business users in hundreds of the world's largest enterprises to be more data-driven with every decision.
The impact of AI on a modern data analyst
Traditionally, the analyst job has consisted of preparing and analyzing data to answer relevant business questions and communicating those insights back to stakeholders so they can take action. For the first part, a lot of automation is making analysts 10X more powerful. The intellectual parts are not going away, but the elimination of rote tasks will enable analysts to do much more high-value work. It is also creating more room for the analyst to focus on impact and communication. In my experience, this often leads to faster promotion for analysts. As an analogy, we are not deploying self-driving cars which would eliminate cab driver jobs. We are upgrading horse carriages to automobiles, which means a lot less dealing with manure and going much faster to longer distances.
Based on what I see in the near future, here is my advice to anyone in the analyst role:
Say no to repetitive data pull requests: Even though your company may need it today, it is detrimental to your career. The time you spend on these requests is all time you are not spending learning modern data stack tools that you’ll need in the future. Occasional requests as exceptions are okay, but if your employer is not willing to invest in the right toolset it’s a red flag for your career growth.
Be the founder of your analytics community: Try and include as many people in analytical decision-making as possible. Educate people on how to use the data models you have built. Educate your organization on data models, interpreting data, and self-service analytics. Educate people on how to make better data-driven decisions. The bigger your community, the more impact you will create. As dbt’s Erica Louie puts it, scaling knowledge > scaling bodies. Things that I have seen work well in this regard are:
Holding regular office hours
Maintaining well documented and searchable data models
Creating tutorials
Hosting internal or external meetups for non-data teams to show off their expertise and share problems
Do more engineering: Learn to automate as many things in your job as you can. If you like, learn python or some other programming tool. You can also consider learning low-code tools for automation and powerful abstractions on top of SQL such as TML or LookML for analytics, or dbt for data pipelines.
Become the product manager for analytics: Most of us engineers pride ourselves on being great problem solvers. What I have learned over the years is that there is a lot more leverage in asking which problems are worth solving and what the end-user actually needs. In the analytics domain, this largely means three things:
Ruthless prioritization: Prioritize work that will generate long-term value, not the urgent request coming from someone with a title. This requires a mature leadership for data teams.
User empathy: The end-user is not always right. If you keep adding new things to your data model based on in-the-moment requests your data model will become completely unusable. Instead, it’s better to understand user needs and synthesize them into a coherent product definition that is usable.
Communication: Being good at communicating complex ideas, influencing opinions, and building consensus are some of the most valuable skills in most careers but are especially important in the analyst role for impact.
Learn the basics of machine learning: The future of data will contain more and more machine learning and it's a useful adjacent skill. Additionally, a big part of improving machine learning models is analytics. If you have a business-critical ML task, you need to be working on potentially hundreds of iterative improvements to the model. This means you need to analyze the error, build a hypothesis on what are the missing features, test those hypotheses with some more analytics, train new ML models, and then analyze their results to establish if you have improved things in each iteration. Even if your primary job is not ML, your analytics skills can be extremely useful to an ML team.
Own the outcome: There has been some debate about whether data teams should be thought of as supporting teams or not. I am a big believer in data teams owning outcomes instead of just having a supporting role for the execution team. For example, your OKR could be helping the Customer Success team reduce churn by 50% or help reduce wasted AWS resources by 30%. This is much more impactful than an OKR like delivering self-service analytics to the Customer Success team. But it requires a level of alignment with the operational teams. It also requires data teams to be able to influence the behavior with data. Accountability without authority can be challenging, however, product managers will tell you that this has always been a part of their job. This is one of the best ways to get yourself a seat at the executive table and put yourself on a fast growth trajectory.
The role of data professionals isn’t going anywhere. Data has never been more important to businesses than it is today – and this importance is only growing in the years ahead. What will change, however, are the skills analysts need to help their organizations build and thrive
It is roughly one year in since you posted this, is there anything you would change here Amit?